



Pandas 데이터 생성
페이지정보
내용
Pandas 기본 사용법
출처 : https://pandas.pydata.org/pandas-docs/stable/getting_started/index.html
pandas는 numpy의 데이터 형이나 계산을 사용하기 때문에 pandas를 사용할때는 numpy도 같이 import 하여 사용한다.
|
import numpy as np import pandas as pd |
1. pandas 데이터 - 1차원 배열을 나타내는 Series
pandas의 데이터는 list나 array 형태로 사용된다.
Series는 1차원 배열의 모양을 한 데이터 오브젝트이다.
Series객체는 아래의 형태를 가진다.
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
Series 생성 예제
|
data_series = pd.Series([1, 2, 3, 4, 5, 'A','B','C', '가','나','다'])
print(data_series) print(type(data_series)) |
결과
|
0 1 |
Series의 데이터를 살펴보면 숫자일 때는 dtype이 int64, int32, float 등이 있으며, 문자열일 경우는 dtype이 object로 설정된다.
또한 Series객체 자체는 pandas의 Series 클래스인 것을 알 수 있다.
여기에서 결과를 살펴보면 두 개의 라인이 출력된 것을 볼 수 있다.
첫번째 라인은 자동으로 출력된 index이다. 모든 리스트는 index를 가지고 있으므로, Series에서도 자동으로 index가 부여된다. index는 0부터 시작하는 정수이다. 만약 index를 임의로 변경하고 싶다면, 두 개의 list를 Series에 입력하거나 dictionary 형태로 입력하면 된다.
1) list로 index 설정하기 - 첫번째 list는 데이터, 두번째 list는 index
|
data_series = pd.Series([1, 2, 3, 4, 5, 'A','B','C', '가','나','다'],['a','b','c','d','e','f','g','h','i','k','k'])
print(data_series) |
결과
|
a 1 |
2) dictionary 형태로 index 설정하기 - key는 index, value는 data
|
data_series = pd.Series({'a':1, 'b':2, 'c':3})
print(data_series) |
결과
|
a 1 |
2. pandas 데이터 - 다차원 배열을 나타내는 DataFrame
DataFrame은 다차원 배열의 데이터이다. DataFrame은 아래의 형식으로 만들 수 있다.
pandas.DataFrame(data=None, index: Optional[Collection] = None, columns: Optional[Collection] = None, dtype: Union[str, numpy.dtype, ExtensionDtype, None] = None, copy: bool = False)
data에 들어갈 수 있는 형태는 numpy.ndarray, dictionary, DataFrame등이 있다.
아래의 데이터를 DataFrame으로 만들어 본다.
| A | B |
| 1 | 5 |
| 2 | 6 |
| 3 | 7 |
| 4 | 8 |
1) ditionarty로 DataFrame 생성 예제
dictionary는 key:value 형태로 구성된다. DataFrame은 입력된 dictionary의 key를 Column값, value는 Row 값으로 처리한다.
따라서 dictionary의 value는 list 또는 Series를 입력할 수 있다.
|
data_frame = pd.DataFrame({'A':[1,2,3,4], 'B':[5,6,7,8]})
print(data_frame ) print(type(data_frame )) |
결과
|
A B |
2) data를 numpy.ndarray 형태로 입력하고, columns값을 따로 정해주는 생성 예제
|
data_frame = pd.DataFrame([[1,5], [2,6], [3,7], [4,8]], columns=['A','B'])
print(data_frame ) |
결과
|
A B |
1)과 2)의 방법으로 만든 DataFrame의 결과는 같다. 다만 1)의 방법에서는 columns에 row를 모두 입력하고 2)의 방법에서는 data를 row의 순서대로 입력해준다.
3) excel 파일 읽어서 DataFrame으로 만들기
많은 데이터를 수작업으로 DataFrame으로 만드는 것은 시간이 매우 많이 걸린다. excel이나 csv에 이미 데이터가 저장되어 있다면, 파일을 읽어서 DataFrame으로 만들 수 있다.
pandas.read_excel(filepath)
아래의 데이터가 저장되어 있는 excel 파일을 읽어서 DataFrame으로 만들어 본다. excel 파일은 첨부된 파일을 이용한다.
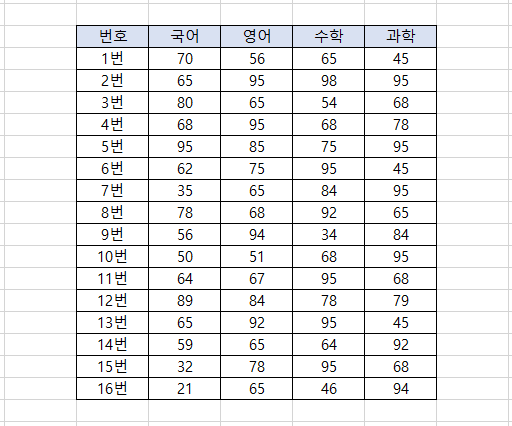
예제 코드
|
import numpy as np import pandas as pd
data = pd.read_excel('datasample.xlsx')
print(data) |
결과
| 번호 국어 영어 수학 과학 0 1번 70 56 65 45 1 2번 65 95 98 95 2 3번 80 65 54 68 3 4번 68 95 68 78 4 5번 95 85 75 95 5 6번 62 75 95 45 6 7번 35 65 84 95 7 8번 78 68 92 65 8 9번 56 94 34 84 9 10번 50 51 68 95 10 11번 64 67 95 68 11 12번 89 84 78 79 12 13번 65 92 95 45 13 14번 59 65 64 92 14 15번 32 78 95 68 15 16번 21 65 46 94 |
4) index 설정하기
DataFrame은 기본적으로 배열의 형태이기 때문에 자동으로 index가 생성된다.
만약 특정 columns 값을 index로 설정하고 싶다면 set_index() 메서드를 사용하여 DataFrame을 재 저장하면 된다.
형식은 다음과 같다. drop을 True로 설정하면 column이 index로 변경된다. drop을 False로 설정하면 column이 유지되며 index가 늘어난다.
DataFrame.set_index(self, keys, drop=True, append=False, inplace=False, verify_integrity=False)
예제 코드
|
import numpy as np import pandas as pd
data = pd.read_excel('datasample.xlsx') print(data)
data = data.set_index('번호') print(data) |
결과
|
번호 국어 영어 수학 과학
|
첨부파일
- datasample.xlsx (11.3K) 17 다운로드 | DATE : 2020-02-28 16:56:37